Project Repo:
View the source code on GitHub
SHA-256 Properties:
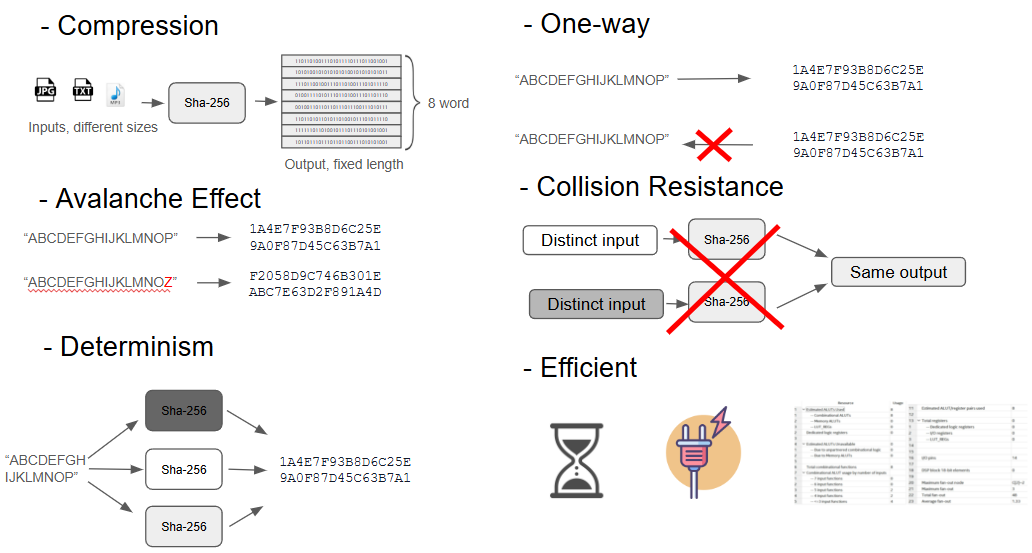
- Compression: Given a variable input size, outputs a fixed length
- Avalanche Effect: A small change in input, even a single character, creates a significant change in the output
- Determinism: The same input will give the same output
- One-Way: No way to reverse engineer the output back to the input, ensuring security
- Collision Resistance: Two distinct inputs have a low probability of producing the same output
- Efficient: SHA-256 balances security and speed.
SHA-256 Algorithm
Our SHA-256 RTL implementation is carefully written to avoid inferred latches and memory blocks, resulting in more predictable synthesis behavior and improved portability. All sequential logic is explicitly registered using always_ff and non-blocking assignments (<=), ensuring no unintended latch generation. Additionally, we use a small, explicitly managed 16-word buffer (w[0:15]) implemented as shift registers, avoiding block RAM inference. This design choice reduces area and makes timing closure more straightforward for ASIC and FPGA targets.
SHA-256 Optimization:
Full parallelism isn’t possible since each block’s hash depends on the previous one, but the word expansion within each block is independent. Instead of computing all expansions first and then compressing blocks sequentially, which creates a long critical path and lowers clock frequency, the more efficient approach is to overlap computation by performing the next block’s word expansion in parallel with the current block’s compression, improving throughput without breaking the dependency chain.
SHA-256 Results:
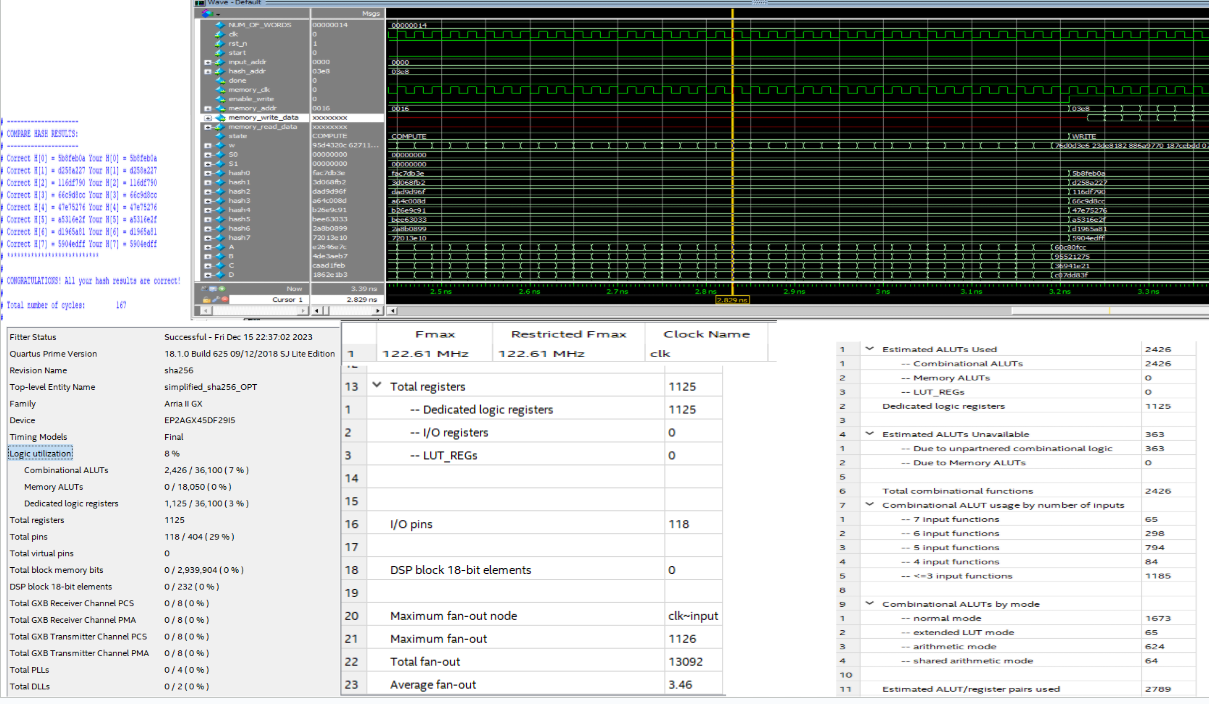
- Device: EP2AGX45DF2915
- Logic utilization: 8%
- Memory ALUTs: 0
- Combinational ALUTs: 7%
- Dedicated Logic Registers: 3%
- Fmax: 122.61 MHz
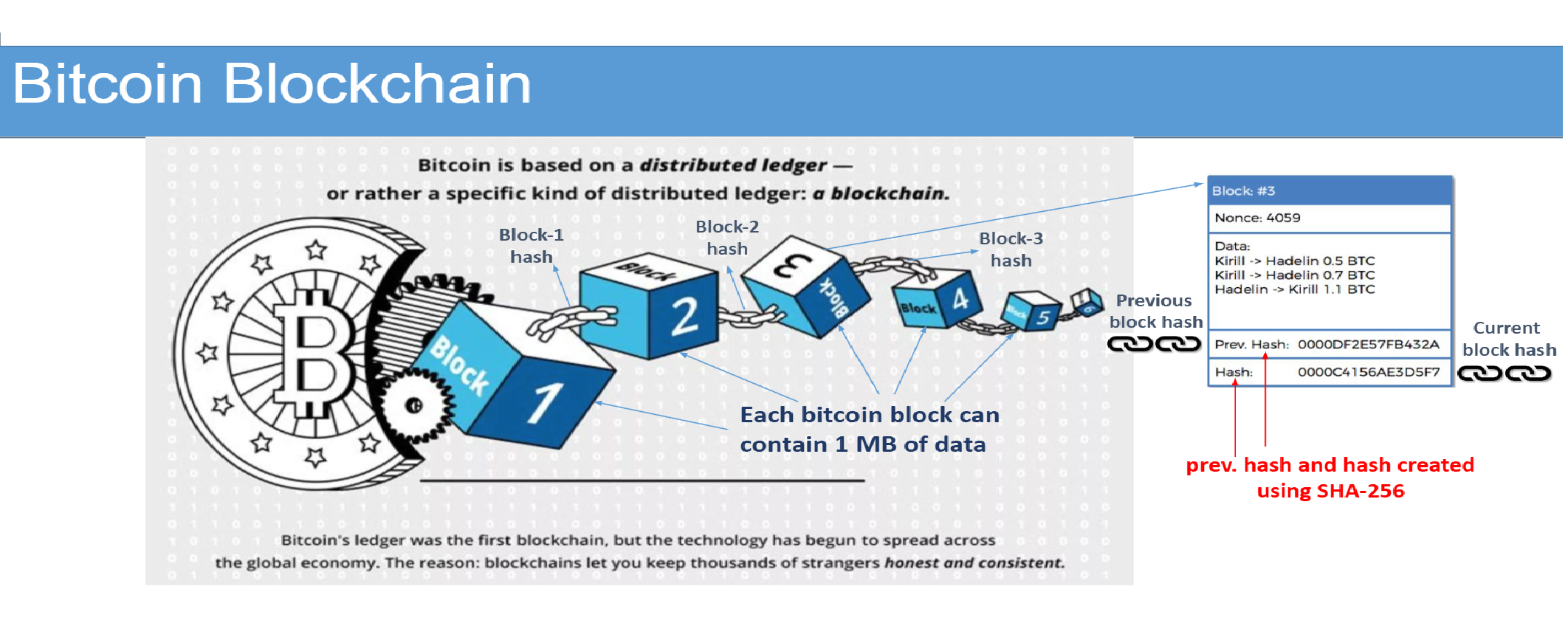
Bitcoin Hashing Algorithm:
Overview:
- Concatenating a 512-bit message block from the 80-byte block header, padded with a 32-bit nonce
- Running the SHA-256 hash function on this message to generate a 256-bit digest
- Applying SHA-256 again on the result to yield the final hash (double SHA-256)
- Comparing or storing
H[0](or full hash) depending on the application
Top-Level Module Parameters and Interfaces:
- The
bitcoin_hash_parmodule takes a block header from memory and computes the double SHA-256 hash across 16 parallel nonces NUM_OF_WORDSdefines the block size;num_noncesis fixed at 16 for parallelism- Standard memory-mapped IO signals handle data exchange with external memory, including
memory_addr,memory_write_data, andmemory_read_data
FSM-Controlled Pipeline:
-
The hashing process is controlled via a six-state FSM:
- IDLE: Initializes state and loads SHA-256 IV constants
- READ: Reads message blocks from memory into the internal W array and inserts padding
- COMP1B: First SHA round for block0. Shared among all nonces—hashes the constant message block
- COMP2B: Second SHA round for all 16 nonces in parallel—each nonce has its own customized W block with its nonce injected
- HASHFIN: Final SHA round. Uses the output of COMP2B as input to a second SHA-256 function (double hashing)
- WRITE: Writes out
H[0]of the final hash result for each nonce
Parallelism and Resource Mapping:
- SHA-256 operations for each nonce are done in parallel, with separate copies of state registers
{A–H}and message schedule buffersw[0:15][nonce]for each nonce - The state machine controls the parallel block updates with for-loops over
current_nonce, enabling 16 nonces to progress through the hashing pipeline simultaneously - This significantly reduces the time to evaluate a batch of nonces versus purely serial designs
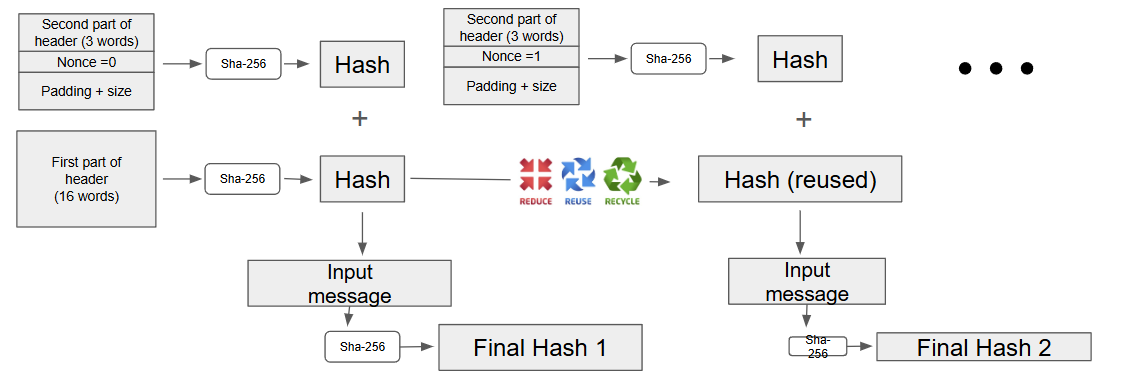
Optimization
The first 19 words are always the same, and each header+nonce message to be hashed is split into two blocks.
Therefore, the first block of 16 is always the same, so its hash is only calculated once.
We save the hash value from this point so we can revert back to this hash value when computing different nonces.
Bitcoin Hashing RTL Module Results
Serial Implementation Results:
- Device: EP2AGX45DF2915
- Logic utilization: 14%
- Memory ALUTs: 0
- Combinational ALUTs: 11%
- Dedicated Logic Registers: 8%
- Fmax: 110.13 MHz
- Total fan-out: 27,414
- Cycles: 2224
Parallel Implementation Results:
- Device: EP2AGX45DF2915
- Logic utilization: 99%
- Memory ALUTs: 0
- Combinational ALUTs: 80%
- Dedicated Logic Registers: 37%
- Fmax: 103.16 MHz
- Total fan-out: 156,898
- Cycles: 241
Conclusion:
Parallel version completed 16 hashes in 241 cycles, or ~15.1 cycles per hash, compared to 2224 cycles per hash in serial.
That’s about a 147× throughput improvement, which corresponds to a 9.2× speed improvement—but comes at the cost of area.
Project Members:
| Shayaun Bashar | Henry Pritchard | (ECE111, Advanced Digital Design Course Project, @UC San Diego Prof. Farinaz Koushanfar) |